
手机图片或者像淘宝这样的网站中的产品图片特点:
(1)、大量手机用户同时在线,执行上传、下载、read等图片操作
(2)、文件数量较大,大小一般为几K到几十K左右
HDFS存储特点:
(1) 流式读取方式,主要是针对一次写入,多次读出的使用模式。写入的过程使用的是append的方式。
(2) 设计目的是为了存储超大文件,主要是针对几百MB,GB,甚至TB的文件
(3) 该分布式系统构建在普通PC机组成的集群上,大大降低了构建成本,并屏蔽了系统故障,使得用户可以专注于自身的操作运算。
HDFS与小图片存储的共通点和相悖之处:
(1) 都建立在分布式存储的基本理念之上
(2) 均要降低成本,利用普通的PC机构建系统集群
(1) HDFS不适合大量小文件的存储,因namenode将文件系统的元数据存放在内存中,因此存储的文件数目受限于 namenode的内存大小。HDFS中每个文件、目录、数据块占用150Bytes。如果存放1million的文件至少消耗300MB内存,如果要存 放1billion的文件数目的话会超出硬件能力
(2) HDFS适用于高吞吐量,而不适合低时间延迟的访问。如果同时存入1million的files,那么HDFS 将花费几个小时的时间。
(3) 流式读取的方式,不适合多用户写入,以及任意位置写入。如果访问小文件,则必须从一个datanode跳转到另外一个datanode,这样大大降低了读取性能。
二、HDFS文件操作流程
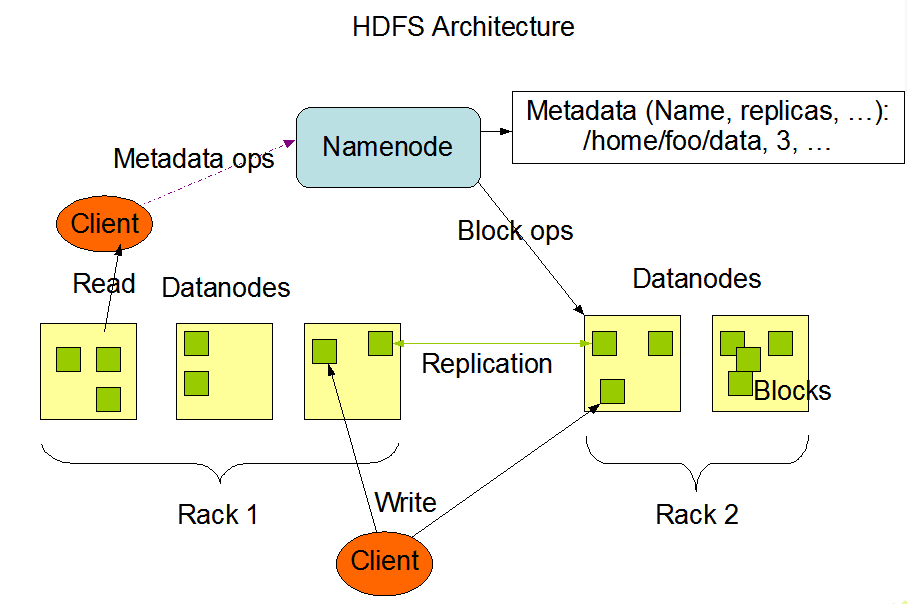
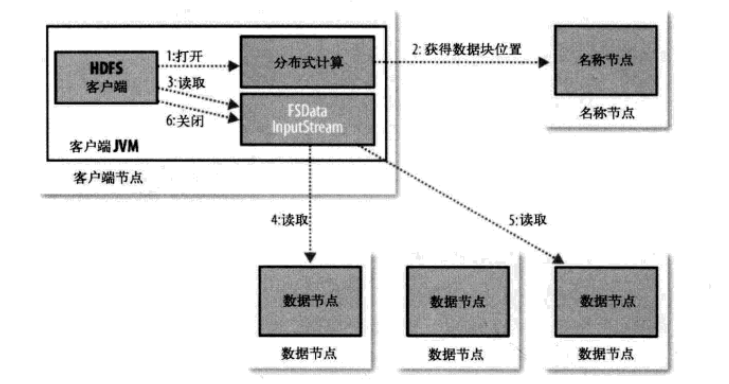
reading:
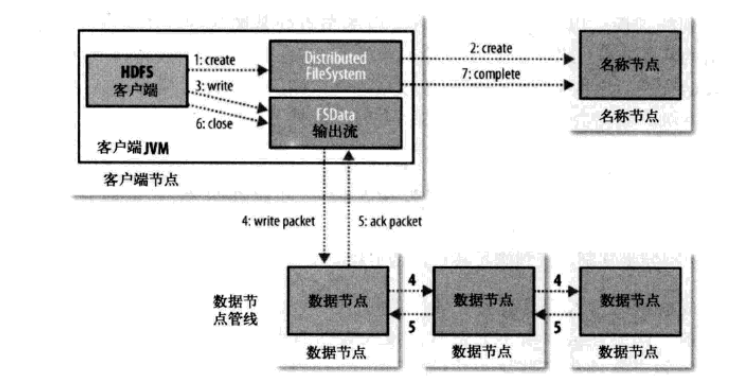
writing:
三、HDFS自带的小文件存储解决方案
对于小文件问题,hadoop自身提供了三种解决方案:Hadoop Archive、 Sequence File 和 CombineFileInputFormat
(1) Hadoop Archive
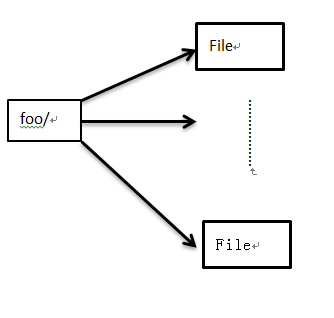
归档为bar.har文件,该文件的内部结构为:
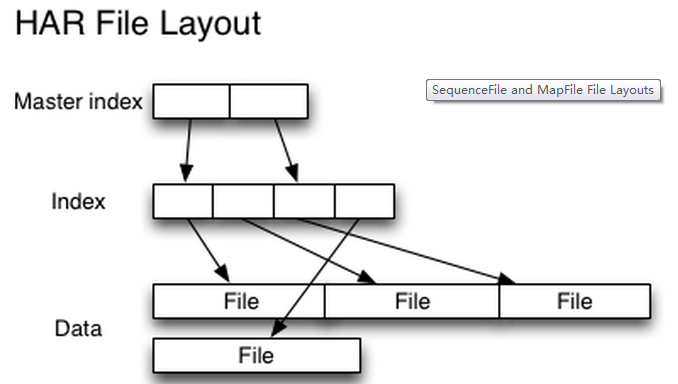
创建存档文件的问题:
1、存档文件的源文件目录以及源文件都不会自动删除需要手动删除
2、存档的过程实际是一个mapreduce过程,所以需要需要hadoop的mapreduce的支持
3、存档文件本身不支持压缩
4、存档文件一旦创建便不可修改,要想从中删除或者增加文件,必须重新建立存档文件
5、创建存档文件会创建原始文件的副本,所以至少需要有与存档文件容量相同的磁盘空间
(2) Sequence File
sequence file由一系列的二进制的
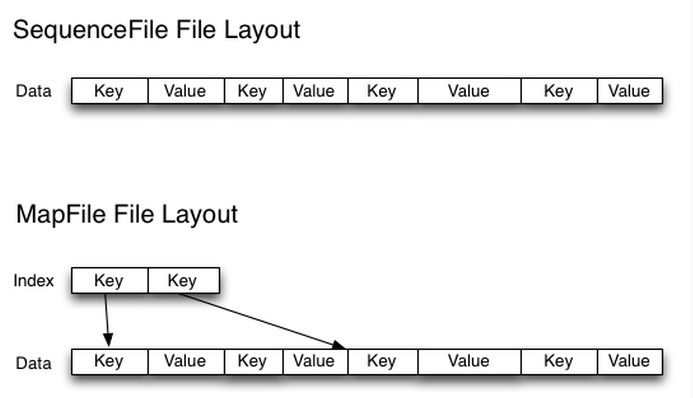
创建sequence file的过程可以使用mapreduce工作方式完成
对于index,需要改进查找算法
对小文件的存取都比较自由,也不限制用户和文件的多少,但是该方法不能使用append方法,所以适合一次性写入大量小文件的场景
(3) CombineFileInputFormat
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
该方案版本比较老,网上资料甚少,从资料来看应该没有第二种方案好。
四、WebGIS解决方案概述
在地理信息系统中,为了方便传输通常将数据切分为KB大小的文件存储在分布式文件系统中,论文结合WebGIS数据的相关特征,将相邻地理位置的小 文件合并成一个大的文件,并为这些文件构建索引。论文中将小于16MB的文件当做小文件进行合并处理,将其合并成64MB的block并构建索引。
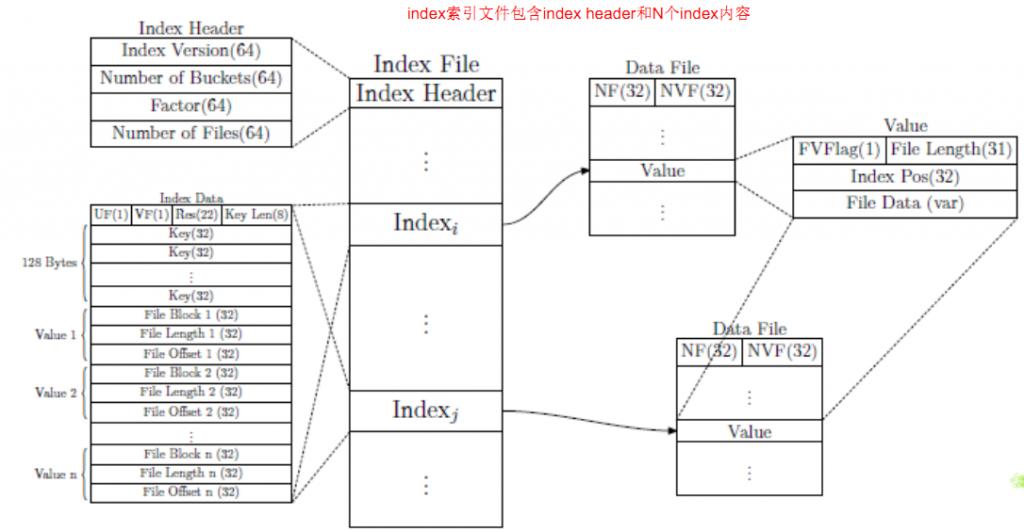
从以上索引结构和文件存储方式可以看出,index是一般的定长hash索引,并且采用的是存储全局index文件的方式
read的过程是将小文件append到下文件后边,然后更新索引的过程
delete文件的过程采用lazy模式,更改的是FVFlag,在空间重新分配的过程中,才会根据该flag删除文件。
五、BlueSky解决方案概述
BlueSky是中国电子教学共享系统,主要存放的教学所用的ppt文件和视频文件,存放的载体为HDFS分布式存储系统。在用户上传PPT文件的 同时,系统还会存储一些文件的快照,作为用户请求ppt时可以先看到这些快照,以决定是否继续浏览,用户对文件的请求具有很强的关联性,当用户浏览ppt 时,其他相关的ppt和文件也会在短时间内被访问,因而文件的访问具有相关性和本地性。
paper主要提出了两个基本观点:
(1) 将属于同一课件的小文件合并成一个大文件,从而减轻namenode的压力,提高小文件的存储效率
(2) 提出了一种两级预取机制以提高小文件的读取效率,(索引文件预取和数据文件预取)索引文件预取是指当用户访问某个文件时,该文件 所在的block对应的索引文件被加载到内存中,这样,用户访问这些文件时不必再与namenode交互了。数据文件预取是指用户访问某个文件时,将该文 件所在课件中的所有文件加载到内存中,这样,如果用户继续访问其他文件,速度会明显提高。
BlueSky上传文件的过程:
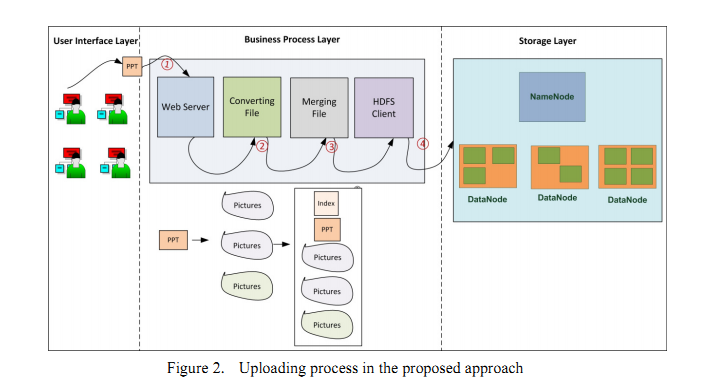
BlueSky阅览文件的过程:
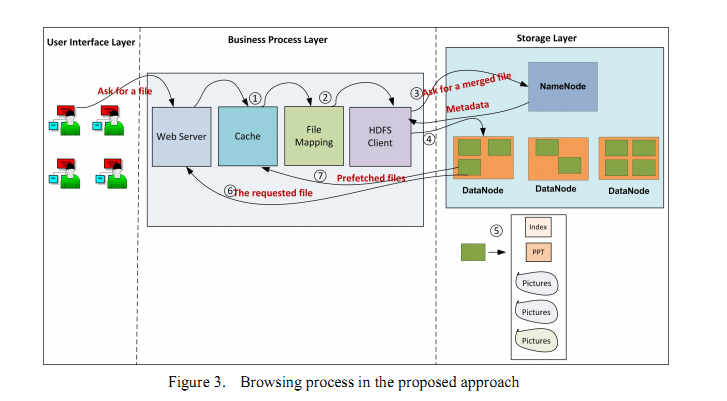
文件合并:
文件合并过程如果合并之后文件的大小小于block64MB的大小则直接存放到一个block中。(合并之后的文件包括local index文件)
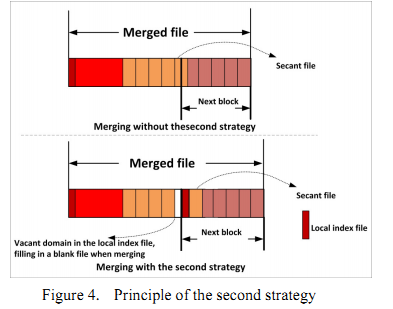
如果合并之后的文件大小大于64MB有两种方式split这个大文件:
1、 local index文件、ppt文件、standresolution picture series存放在一个block中,剩下的picture series存在在其他的block中。
2、 在相邻block的连接处填充空白文件,具体过程:
文件映射:
文件的命名方式,分离的预取图片有其自身的命名方式,具体见paper。文件映射过程中,除了block中的局部索引文件之外,还有一个全局映像文 件。该文件存放的内容为
根据全局mapping table 就可以根据merged file name 和 block Id到namenode上得到datanode的信息,然后到根据
六、facebookHayStack解决方案概述
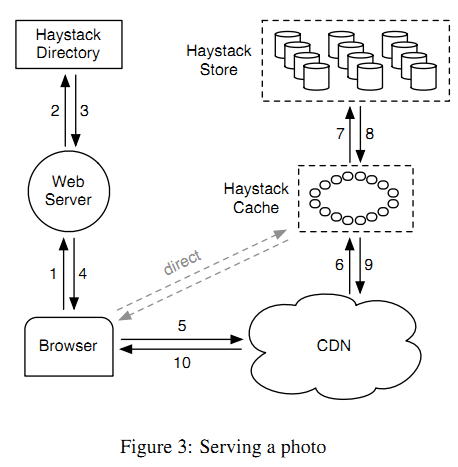
haystack是一个不同于HDFS的分布式系统,如果想在HDFS的基础上构建小文件存储系统,个人认为可以参考借鉴其索引结构的设计。
1、 directory 中有logical volume id<->physicalvolume id。根据
七、TFS解决方案概述
http://code.taobao.org/p/tfs/src/
TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
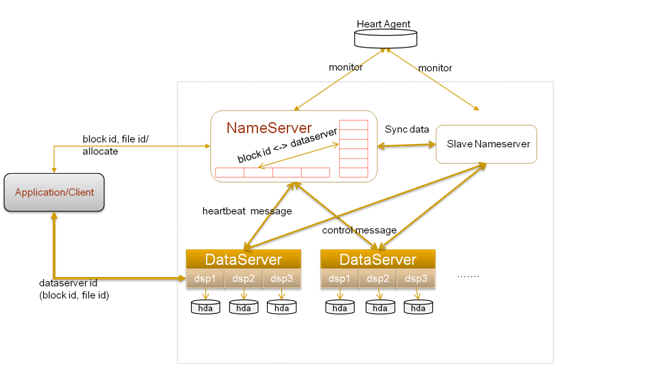
TFS的块大小可以通过配置项来决定,通常使用的块大小为64M。TFS的设计目标是海量小文件的存储,所以每个块中会存储许多不同的小文 件。!DataServer进程会给Block中的每个文件分配一个ID(File ID,该ID在每个Block中唯一),并将每个文件在Block中的信息存放在和Block对应的Index文件中。这个Index文件一般都会全部 load在内存,除非出现!DataServer服务器内存和集群中所存放文件平均大小不匹配的情况。
TFS中之所以可以使用namenode存放元数据信息的一个原因在于不像HDFS的元数据需要存放,filename与block id的映射以及block id与datanode的映射。在TFS中没有file的概念,只有block 的映射信息。所有的小文件被拼接成block。所以namenode中只需要存放
在TFS中,将大量的小文件(实际用户文件)合并成为一个大文件,这个大文件称为块(Block)。TFS以Block的方式组织文件的存储。每一 个Block在整个集群内拥有唯一的编号,这个编号是由NameServer进行分配的,而DataServer上实际存储了该Block。 在!NameServer节点中存储了所有的Block的信息,一个Block存储于多个!DataServer中以保证数据的冗余。对于数据读写请求, 均先由!NameServer选择合适的!DataServer节点返回给客户端,再在对应的!DataServer节点上进行数据操 作。!NameServer需要维

